
私としては、今後の解説につなげていくので良いですが、何人の人に需要があるのかと考えるような、ニッチな企画ですが、今回も書いていきましょう。
【広告】先端AI技術搭載 ファイルを丸ごと翻訳・校正・要約
![]()
差が正規分布になる2つのデータ群とは・・・
言葉だけではわかりにくいと思いますので、それぞれのヒストグラムを示します。
完成品のデータ
乱数A(Table1)と乱数B(Table2)はそれぞれ乱数で発生したものです。
乱数Aは見事に数字が乱数で散っていると思います。それに対して、乱数Bは少し山が見えていますが、それなりに散っています。
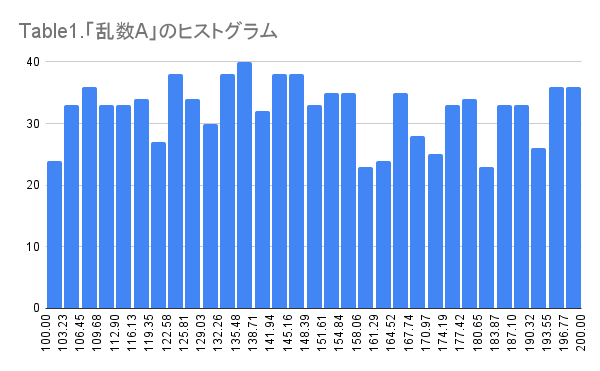
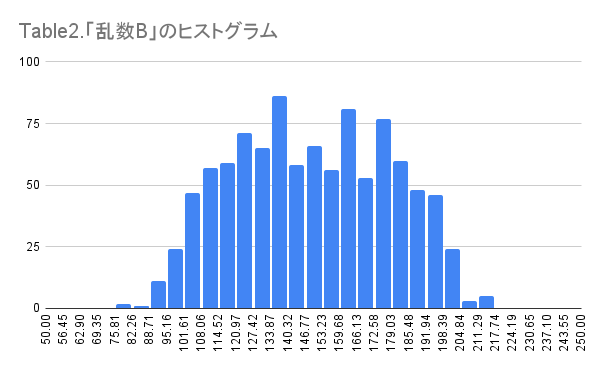
この「乱数A」と「乱数B」の差をヒストグラムにしたものをTable3で示します。
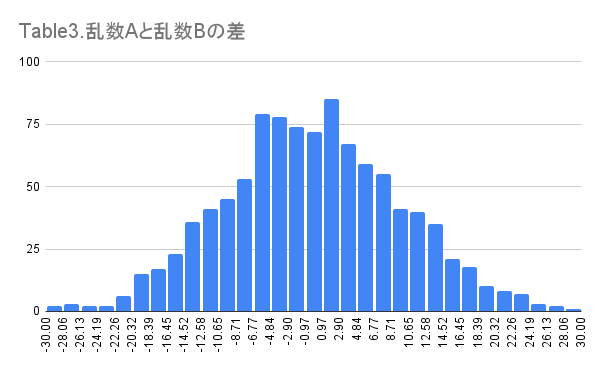
差が正規分布っぽくなっています。このデータは1,000個づつのデータで作ってみましたが、精度はこれくらい。もっと多くのデータにすれば更に正規分布のようなヒストグラムになってきます。
というわけで、作成方法をやっていきましょう。
作成方法
今回の作成方法は下記
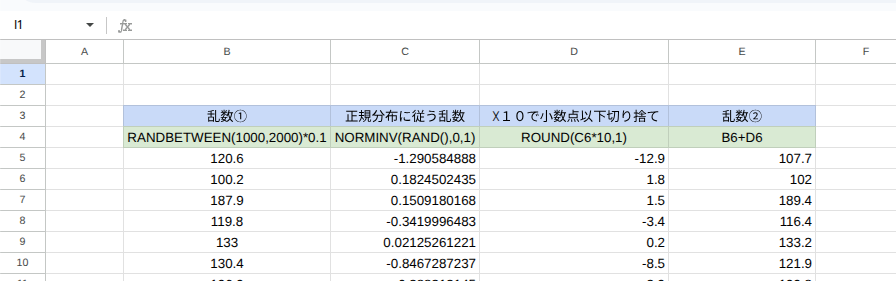
1. RAND関数で乱数を作成(乱数①)
2. NORM.INV関数とRAND関数を用いて正規分布に従う乱数を作成
3. 乱数①に②で作成した正規分布に従う乱数
なお、今回の作成する乱数は「負の数を作らない」、「小数点第一位までの数字」で作成しています。
では、作成しています。では一つづつ解説してみましょう。
①RAND関数で乱数を作成(乱数①)
ここではRAND()を使って作ります。BETWEENRANDを使うと算出される数字が予想しやすいので良いと思います。今回の式は下記
=RANDBETWEEN(1000,2000)*0.1
今回は乱数の中に「負の数」を入れたくないこと、小数点第一位までの乱数を作成するため、範囲を設定後、「0.1」を乗じています。
RAND関数・RANDWBTWEEN関数は 「SpreadSheetsでランダムな値を入力する方法」で、まとめていますので見てみて下さい
②NORM.INV関数とRAND関数を用いて正規分布に従う乱数を作成
次にNORM.INV関数を用いて正規分布に従う乱数を作成します。式は下記。
=NORMINV(RAND(),0,1)
平均値は0・標準偏差「0.1」で作成しました。作成方法は「正規分布に従う乱数の作成方法}でも解説しているので、見てみてください。
今回は「負の数」を作成したくないため、あまり標準偏差を大きくすると負の数を作りやすくなります。そこで重要となる(と考えている?)のは、標準偏差の下記特性。
(平均値)± ( 標準偏差 ) の範囲内に含まれるデータ : 全体の約68%
(平均値)±(標準偏差☓ 2 )の範囲内に含まれるデータ : 全体の約95%
(平均値)±(標準偏差☓ 3 )の範囲内に含まれるデータ : 全体の約99%
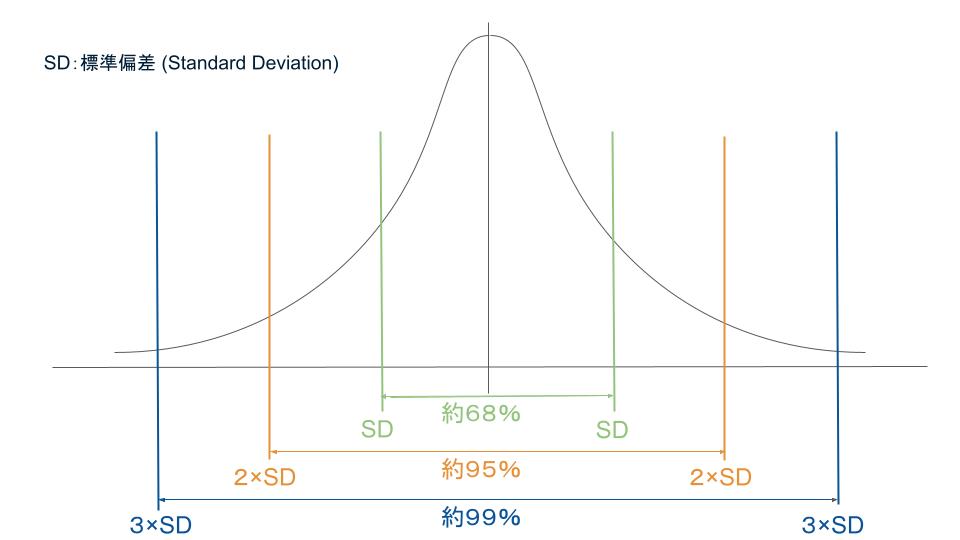
ここで重要なのが、乱数①で作成した最低値から0までの差より、少なくとも(平均値)±(標準偏差☓ 3 )以上、大きくすることが必要です。
ここで算出された乱数をROUND関数を用いて小数点第一位の数字に切り捨てます。
=ROUND((正規分布に従う乱数)*10,1)
ROUND関数は「SpreadSheetsでランダムな値を入力する方法」の後半で解説していますので、見てみてください。
③乱数①から②で作成した正規分布に従う乱数を足す
後は2つの作った乱数を足してあげると乱数②の完成します。
今回使った式は・・・
実際に使った式は4行目の緑のセルになります。
参考になれば幸いです。
なぜ、これを作った?
これから、一つの検体から2つの検査方法を比較するために使用する指標の解説を検討しています。そこで使用しようと作成しました。異なる検査値が同じ結果となるとしても、多少の誤差があると思います。その時には、正規分布に従う形でずれると思うのですよね。
ただ、これは使わないかも⋯⋯
【広告】
![]()

コメント