
解析方法がわかると算出方法は調べられますが、意外とそれは記載していないことが多いんですよね。ですので、私の備忘録も含めてまとめようと思います。違う所があれば、さり気なく教えてください。
今回はある・なしなど、2値の検定を考えています。また、最後に使えるRの関数を記載します。
ていうか、これから使うのでその調べた結果ですね。
注意)ここで記載しているのは解析方法のすべてではありません。また、新しい解析方法が見つかれば、追記します。
まとめ
2項値の解析は下記を検討できます。
対応の無いデータ+2群+期待値が十分
:χ二乗検定
対応の無いデータ+2群+期待値が少ない
:フィッシャーの正確検定
対応のあるデータ+2群
:McNemarの検定
症例数により、通常のMcNemarの検定・McNemarの準正確検定
・McNemarの正確検定と使い分ける
対応のないデータ+3群以上+期待値が十分
:χ二乗検定→χ二乗検定の多重比較(補正が必要)
対応のないデータ+3群以上+期待値が少ない
:フィッシャーの正確確率検定→フィッシャーの正確確率検定の多重比較(補正が必要)
対応のあるデータ+3っ群以上
:cochran Q検定→McNemer検定の多重比較(補正が必要)
ある/なし、成功/失敗などの2値の検定は?
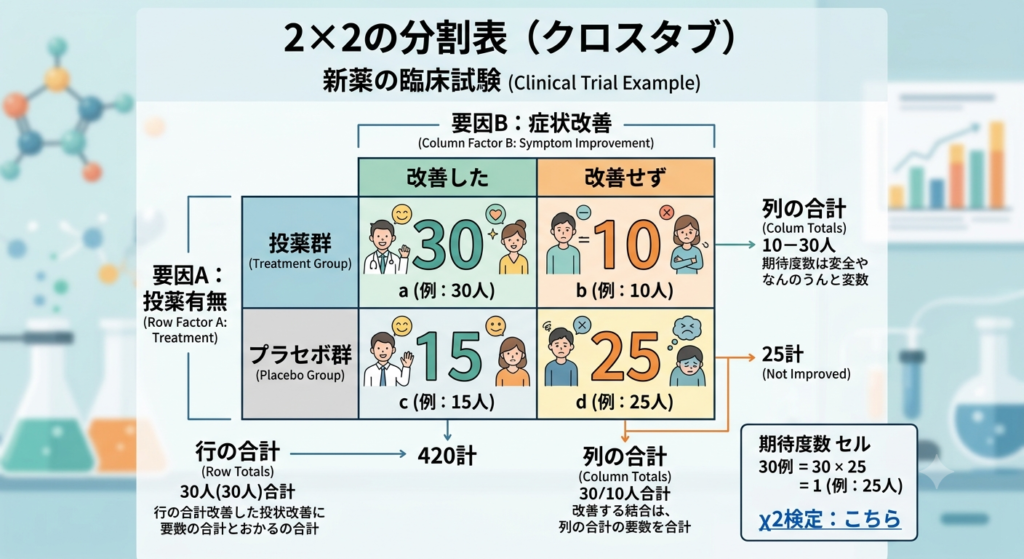
どういうデータかというと、下記の表がその例の一つ。薬剤師らしく臨床試験による例を使ってみました。
縦2種類×横2種類の表ができました。この統計の有意差を確認するのに使用します。
まずは、データの対応があるか考えよう
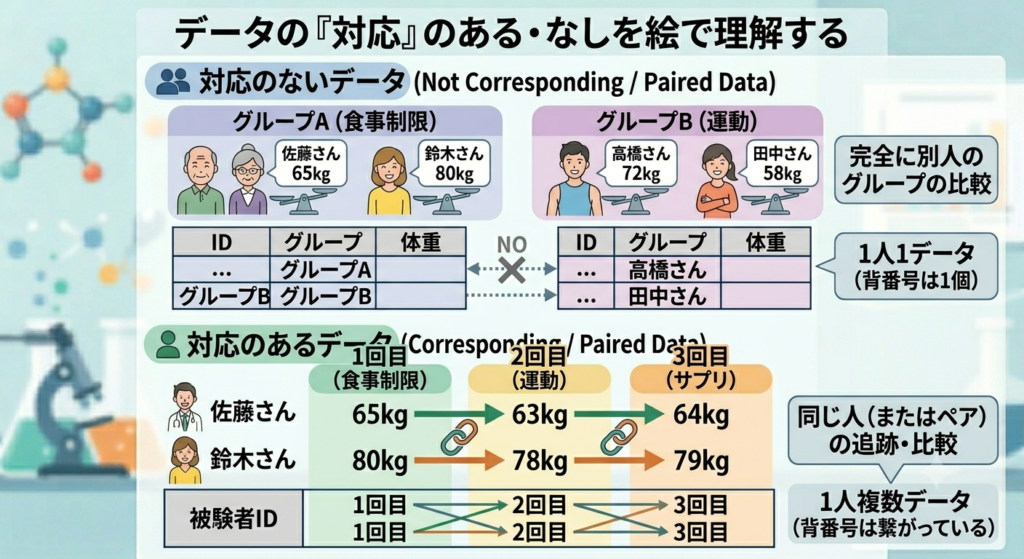
データに対応があるかどうかによって解析方法が異なります。
これがまた、わかりにくい。
この説明は難しいのですが対応のあるデータは、例えば同じ人からのデータを取る、同じものから物からデータを取るなど同じサンプルから複数のデータを取ったものが「対応のあるデータ」となります。
これが別の人、別の物からデータを取る場合には「対応のないデータ」になります。
この理解って難しいですよね。
対応のないデータの解析①:χ二乗検定
有名な統計解析手法が「χ二乗検定」。データが多く、期待度数が大きい時に使いやすい統計方法になります。
ただし、期待度数が5未満のセルが全体の20%以上ある場合、または1未満のセルが1つでもある場合、カイ二乗検定の近似の精度が著しく落ちるため、使ってはいけないとされています。ただ、新しい論文や書籍によって使用の基準は変わる事がある(痛い目にあったこともあり)ので使う時には調べて使うことがおすすめ。
期待度数の計算方法
じゃ、期待度数はどのように計算するかは例を示しながら、下記に記載しました。
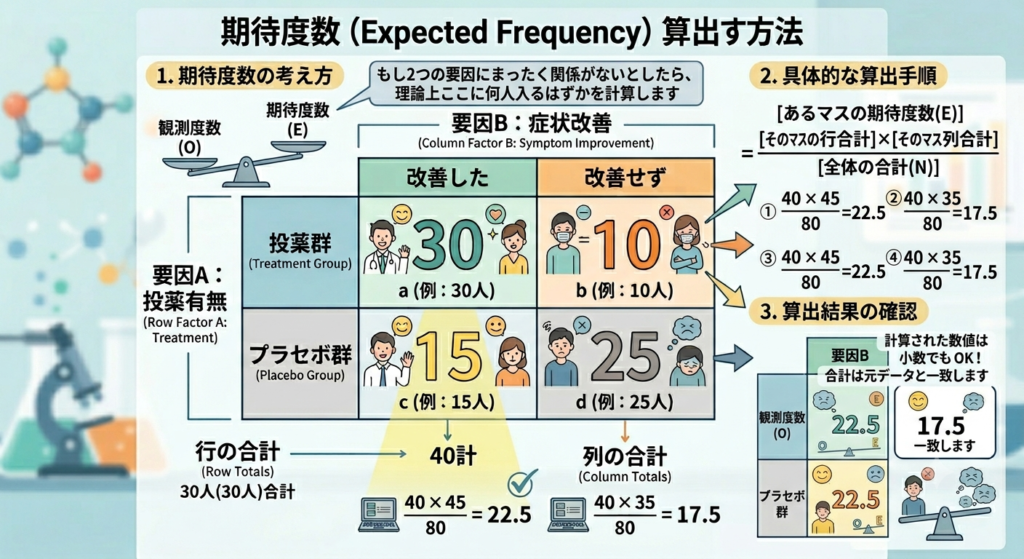
期待度数はそれぞれが影響していないようであればこれくらいの数字だろうという数字(であっていると思います)。この場合だと、「もし薬の効果が全くない(投薬有無と症状改善が独立である)としたら、理論上それぞれのマスに何人が割り振られるか」ということになります。
ベースになっているのは、新薬の臨床試験(計80人)の 2×2 分割表です。
- 要因A(横の行): 投薬群(40人) / プラセボ群(40人)
- 要因B(縦の列): 改善した(45人) / 改善せず(35人)
中央の4つのマスに書かれている「30, 10, 15, 25」という大きな数字は、実際に実験で得られた「観測度数(実際の人数)」です。
右側のエリアでは、4つのマスすべての期待度数をまとめて計算しています。
基本ルールは 「(そのマスの行合計 × 列合計)÷ 全体合計」 です。
- ① 投薬群 × 改善した(左上)
- 式: ( 40 × 45 ) ÷ 80 = 22.5
- ② 投薬群 × 改善せず(右上)
- 式: (40 × 35 )÷ 80 = 17.5
- ③ プラセボ群 × 改善した(左下)
- 式: (40 × 45)÷ 80 = 22.5
- ④ プラセボ群 × 改善せず(右下)
- 式: (40 × 35)÷ 80 = 17.5
表の下側からも、対応するマス(左下と右下)の計算式へ向けて黄色いライトのようなガイドが伸びており、どこから数字を持ってきたかが一目でわかるようになっています。
下記の特徴もあります。
- 小数でもOK: 人なので小数点は本来はありえません(0.2人って腕だけとか??)が、期待値は理論上の数値(平均値のようなもの)なので、22.5人のように小数が出ても問題ありません。
- 合計が一致する: 期待度数を横に足すと 22.5 + 17.5 = 40(行合計)、縦に足すと 22.5 + 22.5 = 45(列合計)になり、元のデータの合計と綺麗に一致します。
つまり、これよりわかるのは下記。
- 実際の人数(観測度数): 投薬群で改善した人は「30人」だった。
- 理論上の人数(期待度数): 薬に効果がなければ「22.5人」のはずだった。
この「30人(実際)」と「22.5人(理論)」のズレ(天秤の傾き)が、偶然では済まされないほど大きいかどうかを判定するのがカイ二乗検定です。今回は実際の人数(30人)のほうが理論値(22.5人)よりもかなり多いため、「新薬には効果がありそうだ」という方向へ天秤が傾いていますが、実際に統計解析を行ってみないとわかりません。
対応のデータ②:フィッシャーの正確確率検定
症例数が少ない場合に使うのが「フィッシャーの正確確率検定」。
これは2×2の分割表の場合によく使用されますが、症例数が少なかったり期待値がχ二乗検定にみたない場合に使用されます。
対応のあるデータ:McNemarの検定
対応のあるデータではMcNemarの検定があります。
この検定は「対応のある2群」の「カテゴリカルデータ(名義尺度・2値データ)」において、前後で割合に有意な変化があったかどうかを調べるためのノンパラメトリック統計検定です。
ただ、注意点としてサンプル数に注意が必要であり、サンプル数が多い場合には良いのですが、少ない場合には検討が必要で、そのためにMcNemar検定にはいくつかある様子。一般的なMcNemar検定のほか、McNemar正確検定(McNemar Exact test)、McNemar準正確検定(Mid-p検定)があるようです。
一般的なMcNemar検定→症例数が必要。
McNemar正確検定 → 症例数が少ない場合の他、目に作成されたが本当は差があるのに「差がない」と結論づけてしまいやすい(検出力が低い)のがデメリット
McNemar準正確検定 → 現在のスタンダードとされる。第一種過誤(5%の基準)を綺麗に保ったまま、正確検定よりも高い検出力を発揮。どの症例数でも対応できる。ただ、認知度が低い?
にて・・・ 使用する場合には、教授・研究仲間・統計の先生などと相談しながら考えていきましょう。というか、Rで解析する時にはこれらの解説が書いてあるけど、他の解析ソフトの場合にはどれを使っているんだろう・・・
3群以上の場合にはどうする?
今は2×2になっていますが、3つ以上の場合にはどうするか・・・
3群以上では基本的には、まず「全体としてグループ間に差があるか(多群比較)」を調べ、有意差があれば「具体的にどことどこの間に差があるか(事後解析/多重比較)」を調べるという2ステップを踏みます。
対応のないデータの解析方法:χ二乗検定→χ二乗検定
多群比較に使用する検定にはχ二乗検定の解析があります。ただ、ここで有意差があっても、3郡のどこかで差があるという証明にしかなりません。つまり、どの群に差があるかはわかりません。
「どの群とどの群の間に差があるのか」を明確に一対一で比較したい場合、表を2群ずつのペアにバラして、個別にカイ二乗検定(またはフィッシャーの正確確率検定)を繰り返します。
例えば、「A群」「B群」「C群」の3群であれば、以下の3つの組み合わせを作ります。
- A群 vs B群 の 2 × 2 分割表で検定
- B群 vs C群 の 2 × 2 分割表で検定
- A群 vs C群 の 2 × 2 分割表で検定
ただし、解析を繰り返して行うため、Bonferroni法やその改良版とされるHolm法など補正を検討する必要があります。
3群以上の対応のあるデータの解析方法:コクランQ検定→McNemar検定
対応のあるデータではコクランのQ検定があります。
この検定でもχ二乗検定と同様にどこかに有意があるということしかわかりません。
「どの群とどの群の間に差があるのか」を明確に一対一で比較したい場合、表を2群ずつのペアにバラして、個別にマクネマー検定を繰り返します。この時も繰り返して行うため、Bonferroni法やその改良版とされるHolm法などの修正を検討する必要があります。
補正方法はどれを選べば良い?
Bonfereroni法・Holm法はP値をいじるだけのため何でも使えるが、個別に見ると検出力がよい、群数が大きくなると有意差が出にくくなるため、他の方法で行った方が良いのではというところ。
多重比較によるP値の補正を考えるうえで必要な情報は、研究の目的とノンパラメトリック・パラメトリックが関連します。
研究目的で言うと、下記の2つの場面があります。
- 「差がある」と結論づけることに絶対の慎重さが求められる場面か(論文の主解析など)
- 大量の項目から「怪しい差」をまずは網羅的に洗い出したい(スクリーニング)場面か
パラメトリックであえば
すべての群で総当りで検索したい:Tukeyの補正
特定の「対照群(コントロール)」とだけ比較したい :『 Dunnett法 』
ノンパラメトリックであれば
検索・スクリーニングに使う:BH法(Benjamini-Hochberg)・強い相関がある場合にも機能するようにBH法を改善したBY法(Benjamini-Yekutieli)
厳密な解析をおこなう+総当りで検定+2項による検定:Bonferroni法(圧倒的に知名度が高い)、群数(10群間比較・20比較などの群)が増えると有意差がでなくなるというBonferroni法を改善したHolm法
2項(YES/ no・ある/なし など)ではなく体重やスコアなど、細かく順位がつけられる「連続変数・順序尺度」であれば下記
厳密な解析+対照群との比較:Steel検定
厳密な解析+総当り:Steel・Dwass法
パラメトリックとノンパラメトリックとは
パラメトリックの「パラメーター」とは、全体の平均値やばらつき(分散)のことです。データが「ある特定の綺麗な形(基本は左右対称の富士山型=正規分布)」をしていることを前提にした統計手法
ノンパラメトリック(Non-)は、データの形に「なんの前提条件(正規分布など)も求めない」という手法です。データがどんなに偏っていても、サンプル数が極端に少なくても(3人だけなどでも)文句を言わずに計算してくれます。
| チェック項目 | パラメトリックを使う条件 | 1つでも当てはまればノンパラメトリック |
| データの種類 | 体重、身長、売上(目盛りが細かい数値) | 5段階評価、ステージ、合格/不合格、順位 |
| データの形 | 基本的には偏りがなく、真ん中が膨らんだ正規分布 | 著しく偏っている、または形が分からない |
これらの検定を”R”で行う時の関数は?
今回の検定をRでおこなう時に使用する関数を書いておきます。
調べた中の関数であり全ては使っていませんが、下記から参考に調べてみてください。p.adjust()はその他の補正にも使用できる関数になります。
こうやって見るとRの関数っていっぱいあるよね。
| 検定方法 | 関数 | package |
| χ二乗検定 | chisq.test() | (標準package) |
| フィッシャーの正確確率検定 | fisher.test() | (標準package) |
| フィッシャーの正確確率検定(多重比較) | pairwise_fisher_test() | rstatix |
| フィッシャーの正確確率検定(多重比較) | fisher_multcomp() | RVAideMemoire |
| コクランQ検定 | cochran.qtest() | RVAideMemoire |
| コクランQ検定 | cochran_qtest() | rstatix |
| コクランQ検定 | cochranQtest() | Desctool |
| McNemar検定 | mcnemar.test() | (標準package) |
| McNemar正確検定(Exact test) | mcnemar.exact() | exact2×2 |
| McNemar準正確検定(Mid-p検定) | mcnemar.exact()midp= Trueにする | exact2×2 |
| McNemar準正確検定(Mid-p検定) | mcnemar.midp() | vcdEstimated |
| McNemar検定(多重比較) | pairwise_mcnemar_test() | rstatix |
| Bonfironi補正などの補正(いろいろ使える) | p.adjust() | (標準package) |
RでCochranQ検定→McNemer検定(補正)の方法の一例は別に記載しました。よろしければ、そちらも読んでみてください。

コメント