
自分の成績は全体のどれくらいか算出するには?
自分の成績がどのくらいなのか、気になったことはありますか?
そんなときに使える関数がNORM.INV関数とNORM.DIST関数です。
目標設定にも使える関数も一緒に解説します。
まぁ、正規分布に従がうという前提がありますが・・・
ちなみにNORM.INV、 NORM.DISTともに、SpreacSheetとEXCELで計算したのを比較しましたが、ほぼ同一の結果でしたので、行っていることは同じと考えても良いと思います。
ということで、今回紹介する関数はこちら
NORM.INV : 指定した値、平均値、標準偏差に対する正規分布の逆関数の値を返します。
NORM.DIST : 正規分布関数ではなく正規累積分布関数
PERCENTILE.INC : データセットの特定のパーセンタイルにおける値を返します。
PERCENTILE.EXC : データセットの特定のパーセンタイルにおける値(0と1を除く)を返す
NORM.INV
NORM.INVはgoogleのヘルプによると
「指定した値、平均値、標準偏差に対する正規分布の逆関数の値を返します。」と、なってます。関数の入力方法は下記。
NORM.INV関数
:指定した値、平均値、標準偏差に対する正規分布の逆関数の値を返します。
【使い方】
NORM.INV(X, mean , SD)
:指定した値、平均値、標準偏差に対する正規分布の逆関数の値を返します。
X : 正規分布関数
mean : 正規分布の平均
SD : 正規分布の標準偏差
この中のXは0〜1(0,1は含まない)の間を指定します。
NORM.INVの計算結果をEXCELとSreadSheetを比較しましたが、ほぼ同じ数値が算出されますのでやっていることはほぼ同じとかんがえていいでしょう。
まずは、この数値がどのように算出されるか見てみましょう。
下記は正規分布の平均30、正規分布の標準偏差30で正規分布関数を0.05刻みで算出した結果になります。

NORM.INVの使い方は?
NORM.INV(X, MEAN, SD)とした時には、正規分布の平均(「MEAN」に入力)と標準偏差(「SD」に入力)を決めて、累積何%となるところ(「X」に入力)では、いくつになるかを算出します
例えば、
あるクラスの身長が165cm平均で、その分布の標準偏差が5だったとします。そのデータが正規分布に従うとした場合、その下位10%(割合に換算して、0.1を入力する)に当たる身長を算出するには、
=NORM.INV( 0.1 , 165 , 5)
で、算出されます。
逆に上位10%であれば、累積分布関数ですので90%累積したときですから、0.9にして
=NORM.INV(0.1, 165 , 5)
となるわけです。
NORM.DIST
これに似た関数でNORM.DISTがあります。
googleのヘルプによると
NORM.DIST関数
指定した値、平均値、標準偏差に対する正規分布関数(または正規累積分布関数)の値を返す。
【使い方】
NORM.DIST(x , 平均 , 標準偏差 , 累積 )
x : 正規分布関数に代入する値
平均 : 正規分布関数の平均値
累積 : 通常の分布関数ではなく正規累積分布関数を使用するかどうかを指定します
True : 正規累積分布関数
False : 正規分布関数
とされています。
累積の部分には「True」「False」が入ります。「True」であれば正規累積分布関数・「False」であれば正規分布関数が算出されます
累積の部分の違いは
累積がFALSEの場合には、分布関数が算出されます。
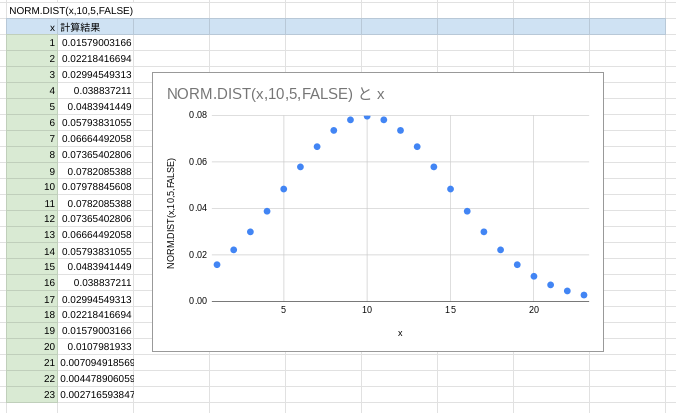
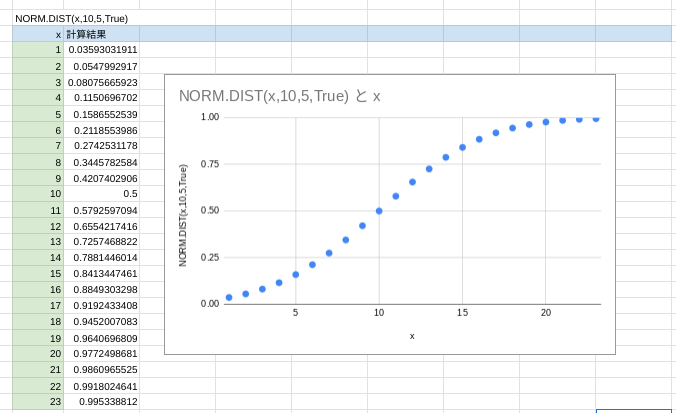
それに対して、Trueの場合には正規累積分布関数が算出されます。
「累積」なので、1へ向かって徐々に積みあがっていくのが分かります。
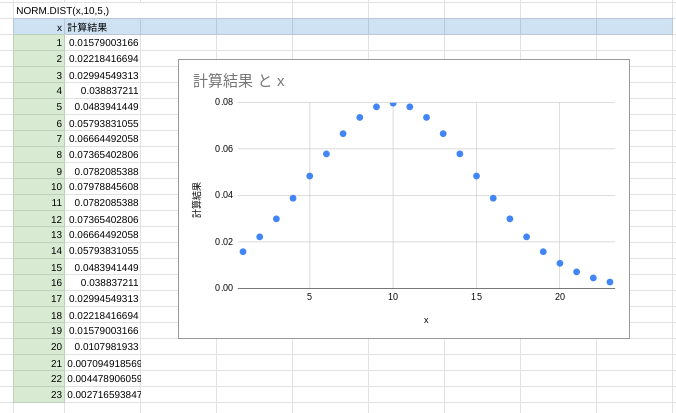
ちなみに、False Trueどちらも入力しないと分布関数が算出されます。
どのように使う?
正規分布の平均と標準偏差を指定して、いくつのときには累積何%となるかを算出する場合に使いますが、このままだと分かりにくいかと。
例で示すのが想像がつきやすいと思いますので、先ほどと同様の例題で行うと、
身長が165cm平均で、その分布の標準偏差が5としたときに、170cmの方が下位何%かを確認するためには
NORM.DIST(170,165,5,True)
とすれば、算出されます。
この2つの使い分けは?
テストの得点の分布が 平均点:50点 標準偏差:20の分布で、自分の点数を60点とします。(このテスト結果で凹むか、嬉しく感じるかは個人によりますが・・・)
この分布が正規分布に従うと仮定した場合、どの程度の順位(今は上位、何%?)になるかを算出するのにNORM.DISTを使用します。これで現在の状態を確認!!
じゃ、今後の目標を
どの順位(上位、何%にはいるには?)に入るのはどのくらいの点数を取れば使用できるか、を算出するにはNORM.INVを使用して算出することができます。
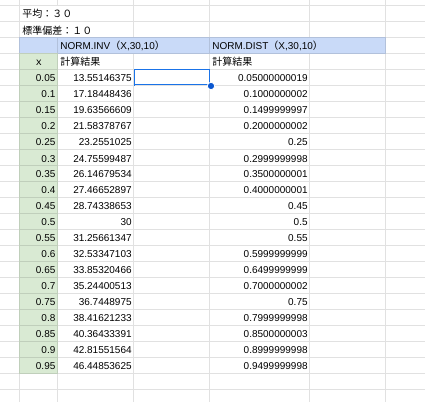
ちなみに、NORM.INVでの計算結果をNORM.DISTで元にもどすと・・・
NORM.INVで算出された正規分布の逆関数をNORM.DISTで戻すことをしました。
つまり、左側の2行目が平均を30、標準偏差、正規分布関数を1行目(緑の行)に示した数値でNORM.INVで算出したものになります。この2行目の数字をNORM.DIST(X , 30 , 10 , True)のXのところに代入しました。
わずかに差はあるものの、算出された結果は、1行目(緑の行)と同様の数値となっています。差ができるのは切り捨てなどの影響だとは思います。
EXCELだと全く同じ数字がでますが、よほど精密な作業を行わない限りは差はないと考えていいと思います。
じゃ、正規分布に従わなかったら?
SpreadSheetで使える関数にはPERCENTILE.INC関数・PERCENTILE.EXC関数があります。
PERCENTILE関数もありますが、PERCENTILE.INC関を調べるとPERCENTILE関数を参照になるため、使い方は同じですので、実質は2つ。では順に見てみましょう。
PERCENTILE
PERCENTILE.INC関数
データセットの特定のパーセンタイルにおける値を返します。
【使い方】
PERCENTILE.INC(Data, Percentile)
data:検証するデータセットを含む配列または範囲
Percentile:データ内の計算結果となる値のパーセンタイル(0~1の範囲)
PERCENTILE.EXC関数
データセットの特定のパーセンタイルにおける値(0と1を除く)を返す
【使い方】
PERCENTILE.EXC(Data, Percentile)
Data:検証するデータセットを含む配列または範囲
Percentile:データ内の計算結果となる値のパーセンタイル(0~1の範囲,0・1は含まない)
この2つの関数の違いは0と1を除くかどうかにあります。
使い方は?
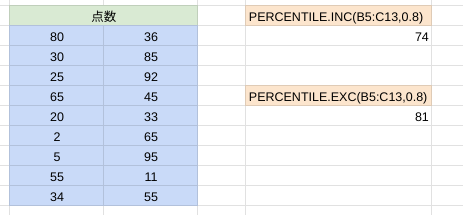
下記の点数のデータをもとに上位20%に当たる数値を算出しました。
Dataは点数の数値(青のセル)をDataとし、Percentileは上位20%なので、下位から考えると80%、割合で入力するので、最終的には0.8を入力しています。
PERCENTILE.INC(B5:C13,0.8)(上のオレンジのセル)とPERCENTILE.EXC(B5:C13,0.8)(下のオレンジのセル)、それぞれの下に計算結果が表示されています。
下記より全部のデータを使った場合にはPERCENTILE.INC関数になるので「74」、0と1を除いて計算した場合にはPERCENTIE.EXC関数になるので「81」になります。
【広告】
![]()
参考)
Gooleドキュメント エデュターヘルプ NORM.INV
https://support.google.com/docs/answer/9387356?hl=ja
Gooleドキュメント エデュターヘルプ NORM.DIST
https://support.google.com/docs/answer/9387094?hl=ja
Gooleドキュメント エデュターヘルプ PERCENTILE
https://support.google.com/docs/answer/9387590?hl=ja
Gooleドキュメント エデュターヘルプ PERCENTILE.EXC
https://support.google.com/docs/answer/9368167?hl=ja

コメント